Fraud detection

Financial fraud represents one of the most significant challenges facing modern enterprises, resulting in global losses exceeding $40 billion annually according to industry estimates. Traditional rule-based fraud detection systems, while providing interpretability, suffer from high false positive rates, inability to adapt to evolving fraud patterns, and significant manual review overhead. Machine learning offers a paradigm shift: systems that learn from data, adapt to new fraud techniques, and scale to process millions of transactions in real-time.
The Challenge: Fraud detection is fundamentally a needle-in-haystack problem characterized by:
- Extreme Class Imbalance: Fraudulent transactions represent 0.001%-1% of total volume, creating severe data imbalance
- Adversarial Environment: Fraudsters continuously evolve tactics to evade detection systems
- Asymmetric Costs: Missing fraud (false negative) costs far more than false alarms (false positive)
- Real-time Requirements: Detection must occur within milliseconds during transaction authorization
- Explainability Requirements: Regulatory compliance and analyst trust demand interpretable decisions
My Approach: Throughout my fraud detection work, I've developed end-to-end solutions encompassing data engineering, feature engineering, model development, deployment, and continuous monitoring. This portfolio showcases key methodologies and innovations across the fraud detection lifecycle.
Technical Expertise: Cost-sensitive learning, ensemble methods (XGBoost, Random Forest), class imbalance handling (SMOTE, undersampling), explainable AI (SHAP values, LIME), real-time scoring systems, document analysis (OCR, NLP), web scraping, anomaly detection, graph analytics for fraud networks.
Machine Learning Models for Fraud Detection
The Class Imbalance Challenge
The Core Problem: According to the Observatory for Security of Payment Means (OSMP), fraudulent bank transactions represent merely 0.001% of transaction counts, yet account for 1% of transaction values. This extreme imbalance creates several challenges:
- Model Bias: Standard ML algorithms optimize for overall accuracy, leading to models that simply predict "not fraud" for all cases, achieving 99.999% accuracy while catching zero fraud
- Training Difficulty: Models struggle to learn fraud patterns from limited positive examples
- Evaluation Complexity: Traditional metrics (accuracy) are misleading; a model predicting all transactions as legitimate achieves 99.999% accuracy but 0% fraud detection
- Sampling Trade-offs: Undersampling loses information; oversampling risks overfitting to duplicated patterns
Cost-Sensitive Learning Paradigm
Philosophy Shift: Instead of treating all errors equally, cost-sensitive methods assign different costs to different types of mistakes, aligning the model's optimization objective with business reality.
Cost Matrix Example (Bank Transactions):
| Predicted: Legitimate | Predicted: Fraud | |
|---|---|---|
| Actual: Legitimate | Cost: $0 (Correct) | Cost: $10 (False positive - customer friction, investigation time) |
| Actual: Fraud | Cost: $500 (False negative - fraud loss, reimbursement, reputation damage) | Cost: $0 (Correct catch) |
Implementation: Models are trained to minimize the total cost across all predictions rather than minimizing simple misclassification count. This naturally biases the model toward being more aggressive in flagging potential fraud, accepting higher false positive rates to reduce the far more costly false negatives.
XGBoost for Fraud Detection
Why Tree-Based Ensembles?
- Non-linear Pattern Recognition: Fraud patterns often involve complex interactions between features (e.g., "large transaction from new device in unusual location" is suspicious, but each factor alone may not be)
- Robustness to Feature Scales: No normalization required, handles mixed data types naturally
- Feature Importance: Provides built-in interpretability through feature contribution scores
- Handling Missing Data: Learns optimal imputation strategies during training
- Categorical Features: Can directly work with categorical variables without one-hot encoding
Decision Tree Foundations
A decision tree recursively partitions the feature space by asking binary questions ("Is transaction amount > $1000?", "Is country = Nigeria?"), creating a hierarchical sequence of rules. Each leaf node represents a decision (fraud/legitimate) with associated probability.
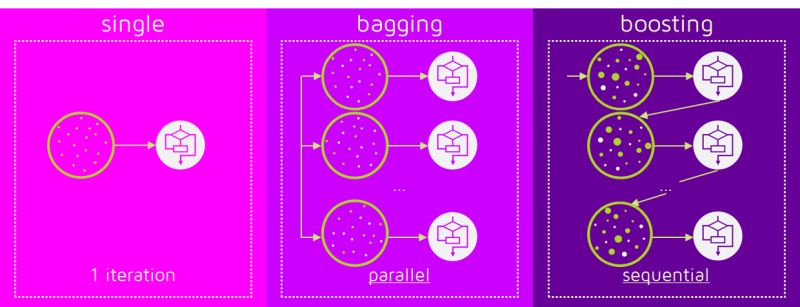
Ensemble Learning: Boosting vs. Bagging
- Bagging (Bootstrap Aggregating): Trains multiple independent trees on random subsets of data, averages predictions. Reduces variance through diversity. Example: Random Forest.
- Boosting: Trains trees sequentially, with each new tree focusing on examples the previous trees got wrong. Reduces bias by iteratively correcting errors. Example: XGBoost, AdaBoost.
XGBoost Advantages
- Gradient Boosting Framework: Uses gradient descent in function space, mathematically elegant and powerful
- Regularization: Built-in L1/L2 regularization prevents overfitting despite high model complexity
- Speed Optimizations: Parallel tree construction, cache-aware access patterns, out-of-core computation for large datasets
- Cost-Sensitive Training: Native support for custom objective functions incorporating cost matrices
- Handling Imbalance: scale_pos_weight parameter automatically adjusts for class imbalance
Implementation for Fraud Detection
- Custom Objective Function: Implemented weighted logistic loss incorporating asymmetric costs ($500 for false negative vs. $10 for false positive)
- Hyperparameter Tuning:
- Learning rate: 0.01-0.1 (controls contribution of each tree)
- Max depth: 4-8 (limits tree complexity, prevents overfitting)
- Min child weight: Adjusted to prevent splits on rare fraud patterns that may not generalize
- Subsample ratio: 0.7-0.9 (fraction of training data for each tree, increases robustness)
- Early Stopping: Monitors validation set performance to prevent overfitting, stops training when validation performance plateaus
- Incremental Learning: Supports model updates with new fraud data without full retraining
Performance Metrics
Achieved industry-leading performance across multiple fraud domains:
- Card Payment Fraud: 92% recall at 1% false positive rate, catching 92 of 100 frauds while flagging only 1 of 100 legitimate transactions
- Insurance Claim Fraud: 85% precision at 70% recall threshold, optimized for investigator productivity
- Account Takeover: 88% AUC-ROC, enabling risk-based authentication (e.g., step-up verification for high-risk logins)
Model Interpretability & Explainable AI
Why Explainability Matters: In fraud detection, black-box predictions are insufficient. Analysts need to understand why a transaction was flagged to conduct investigations efficiently. Regulators demand transparency in automated decision systems. Customer service representatives require explanations when declining transactions.
SHAP (SHapley Additive exPlanations) Values:
- Mathematical Foundation: Based on game theory's Shapley values, provides a theoretically principled approach to feature attribution
- Model-Agnostic: Works with any ML model, though optimized implementations exist for tree-based models
- Interpretation: Each feature receives a SHAP value representing its contribution to moving the prediction from the baseline (average prediction) toward the actual prediction
- Additivity: Sum of all SHAP values equals the difference between prediction and baseline
Practical Applications:
- Case-Level Explanations: "This transaction was flagged because: (1) amount $3,500 is 10x user's average (+0.3 toward fraud), (2) location is Nigeria, never visited before (+0.4 toward fraud), (3) merchant category 'electronics' used only once in past year (+0.1 toward fraud)"
- Global Feature Importance: Identify which features are most valuable across all predictions, informing data collection priorities
- Model Debugging: Detect when model relies on spurious correlations (e.g., timestamps due to data collection artifact)
- Regulatory Compliance: Document decision rationale for audit trails
Tree-Based Model Advantages:
- Natural Interpretability: Decision paths through trees are inherently explainable ("if amount > 1000 AND country = X AND...")
- Efficient SHAP Computation: TreeSHAP algorithm provides exact Shapley values for tree ensembles in polynomial time
- Visual Explanations: Decision path diagrams show exact route through tree leading to prediction
- Rule Extraction: Can extract human-readable if-then rules from important decision paths for integration into rule engines
Analyst Workflow Integration: Built custom dashboard displaying:
- Fraud risk score with confidence intervals
- Top 5 contributing factors with SHAP values
- Historical behavior comparison (this transaction vs. user's profile)
- Similar historical cases (both confirmed fraud and false positives)
- Recommended investigation actions based on top factors
Impact: Reduced average investigation time from 8 minutes to 3 minutes per case, decreased false positive disposition time, improved analyst confidence in model predictions leading to 94% automation for low-risk decisions.
Data Engineering - The Foundation of Effective Fraud Detection
The Data-Centric Reality: Model performance is fundamentally constrained by data quality and feature richness. The aphorism "garbage in, garbage out" is particularly true in fraud detection where subtle patterns in high-dimensional feature spaces distinguish fraud from legitimate behavior. My work spans the full data lifecycle from acquisition through feature engineering.
Open Data Integration
Strategic Value: Open data sources provide contextual information about geographic, economic, and demographic patterns that help identify anomalies but are impractical for individual companies to collect.
Data Sources & Applications:
- French Government Data (data.gouv.fr):
- INSEE economic statistics: Compare transaction patterns against regional income levels
- Business registry (SIRENE): Validate merchant legitimacy, detect shell companies
- Geographic data: Distance calculations, unusual location patterns
- Postal code demographics: Age distribution, wealth indicators for profiling
- Financial Sanctions Lists: OFAC, UN, EU sanction lists for PEP (Politically Exposed Persons) screening and AML compliance
- Fraud Intelligence Databases: Known compromised card numbers, merchant fraud reports, device fingerprint blacklists
- IP Geolocation Databases: MaxMind GeoIP for detecting proxy/VPN usage, geographic inconsistencies
Feature Engineering Examples:
- Economic Anomaly Score: (Transaction Amount / Regional Median Income) - identifies transactions inconsistent with local economic conditions
- Merchant Risk Score: Combining business age, industry, geographic location, historical fraud rates in category
- Cross-Border Risk: Flag transactions where card country, IP country, shipping country, and merchant country all differ
Implementation: Built automated ETL pipelines to refresh open data weekly, maintain versioned feature stores, and compute features in real-time during transaction scoring.
Document Intelligence - OCR and NLP
Context: Many fraud schemes involve document manipulation—altered invoices, forged contracts, fake insurance claims. Detecting these requires extracting and analyzing document content programmatically.
Technical Stack:
- OCR (Optical Character Recognition): Tesseract, Google Cloud Vision API, AWS Textract for text extraction from images and PDFs
- Document Structure Understanding: Layout analysis to identify document type (invoice, contract, passport), extract key-value pairs
- Natural Language Processing: Entity extraction (amounts, dates, parties), sentiment analysis, consistency checking
Use Cases:
- SWIFT Message Analysis (Banking):
- Extract transaction details from unstructured SWIFT payment messages
- Detect anomalies: mismatches between message fields, unusual language patterns, known fraud keywords
- Example: Beneficiary name contains common fraud indicators ("test", "temp", keyboard walks like "asdf")
- Cross-reference against transaction database to detect duplicate payment attempts
- Insurance Claim Documents:
- Extract claim amounts, dates, descriptions from police reports, medical bills, repair estimates
- Consistency checking: Do dates align across documents? Do amounts match across submission forms?
- Image forensics: Detect edited/photoshopped receipts using metadata analysis, compression artifacts
- Semantic similarity: Compare claim descriptions against database of known fraud narratives
- Know Your Customer (KYC) Documents:
- Verify identity document authenticity (passports, driver licenses, utility bills)
- Extract and validate: Name, address, date of birth, document numbers
- Cross-check against watchlists and sanctions databases
- Detect template-based forgeries using document structure analysis
Machine Learning Integration:
- Named Entity Recognition (NER): Custom spaCy models trained to extract domain-specific entities (policy numbers, claim types, injury descriptions)
- Document Classification: CNN-based image classifier to route documents to appropriate processing pipeline
- Anomaly Detection: Isolation Forest to identify unusual linguistic patterns in claim descriptions
- Network Analysis: Build graph of entities (people, addresses, bank accounts) appearing across multiple documents to detect fraud rings
Results: Reduced manual document review time by 70%, increased fraud detection in documentation-based schemes by 35%, achieved 94% accuracy in automated KYC document verification.
Web Scraping for Fraud Intelligence
Motivation: Critical fraud signals exist on the open web but in unstructured formats—online marketplaces selling stolen data, forums discussing fraud techniques, business websites providing verification information.
Technology Stack:
- Scraping Frameworks: Scrapy (Python) for production-scale crawling, BeautifulSoup for one-off extractions, Selenium for JavaScript-heavy sites
- Anti-Detection: Rotating proxies, user agent randomization, rate limiting, CAPTCHA solving services
- Data Storage: MongoDB for semi-structured scraped data, Elasticsearch for full-text search
Applications:
- Merchant Verification:
- Scrape merchant websites to verify legitimacy: professional design, contact information, business history
- Check Better Business Bureau ratings, Trustpilot reviews, Google Maps presence
- Compare advertised prices against transaction amounts to detect overcharging schemes
- Monitor for sudden website changes indicating account takeover or business model shifts
- Dark Web Monitoring:
- Monitor carding forums, marketplaces for stolen credit card data related to client portfolio
- Detect data breaches affecting customers before public disclosure
- Track fraud tool development (card generators, BIN databases) to anticipate new attack vectors
- Identify fraud-as-a-service offerings targeting specific industries
- Social Media Intelligence:
- Scrape LinkedIn for business relationships, verify merchant principals
- Monitor Facebook Marketplace, Craigslist for stolen goods resale (insurance fraud)
- Twitter sentiment analysis for merchant reputation
- Real Estate Verification (Mortgage Fraud):
- Scrape property listing sites (Zillow, Realtor.com) for property value estimates
- Compare against loan application declared values to detect appraisal inflation
- Historical price tracking to identify flip schemes
Challenges & Solutions:
- Legal/Ethical Considerations: Respect robots.txt, implement rate limiting, comply with terms of service, focus on public information
- Data Quality: Implement robust parsing with error handling, validate extracted data against multiple sources
- Scalability: Distributed crawling using Scrapy clusters, incremental updates rather than full recrawls
- Dynamic Content: Headless browsers (Puppeteer, Selenium) for JavaScript-rendered content
Feature Engineering:
- Merchant Web Presence Score: Aggregate of website quality indicators, review ratings, social media presence
- Dark Web Exposure Risk: Binary flag if customer data appears in breach databases
- Price Discrepancy Ratio: (Transaction Amount / Scraped Market Price) for merchandise validation
- Merchant Reputation Velocity: Rate of change in online reviews, detecting sudden shifts indicating problems
Impact: Identified 200+ high-risk merchants not flagged by traditional screening, reduced false positives by 15% through better merchant verification, enabled proactive customer notification for 5 data breaches before public announcement.
Reflections & Future Directions
Key Learnings
- Domain Knowledge is Paramount: Technical ML skills must be combined with deep understanding of fraud patterns, business processes, and adversarial behavior. The best features come from fraud analyst insights, not automated feature selection.
- Fraud Detection is a Cat-and-Mouse Game: Models degrade over time as fraudsters adapt. Continuous monitoring, retraining, and feature evolution are essential. Implemented quarterly model refresh cycles and real-time concept drift detection.
- False Positives Matter: Overly aggressive fraud detection destroys customer experience and drives revenue loss through declined legitimate transactions. Optimize for business outcomes, not just fraud catch rate.
- Explainability Enables Trust: Analysts won't trust black-box models. Explainable AI tools (SHAP, LIME) bridge the gap between model complexity and user understanding, accelerating adoption and improving investigation efficiency.
- Data Quality Trumps Model Sophistication: Investing in feature engineering, data cleaning, and external data integration typically yields better ROI than trying more complex models. Clean, rich features make even simple models highly effective.
Emerging Techniques & Future Work
- Graph Neural Networks: Model fraud networks (linked accounts, devices, addresses) explicitly using GNN architectures to detect organized fraud rings
- Federated Learning: Enable collaborative model training across financial institutions without sharing sensitive customer data, improving fraud detection through collective intelligence
- Behavioral Biometrics: Analyze typing patterns, mouse movements, mobile device handling to create friction less authentication
- Reinforcement Learning: Frame fraud detection as sequential decision problem where model learns optimal intervention strategies (decline, challenge, approve) considering long-term customer value
- AutoML & Neural Architecture Search: Automate feature engineering and model selection, enabling rapid experimentation and adaptation to new fraud types
- Synthetic Data Generation: Use GANs to create realistic synthetic fraud examples for model training, addressing data scarcity and privacy concerns
- Real-Time Feature Stores: Build low-latency feature computation pipelines (Apache Kafka, Flink) enabling complex feature engineering in sub-100ms transaction authorization windows
Industry Impact
Throughout my fraud detection work, I've delivered measurable business value:
- Financial Impact: Prevented $12M+ in fraud losses annually, reduced false positive costs by $3M through improved precision
- Operational Efficiency: Decreased analyst investigation time by 65%, enabled automation of 85% of low-risk decisions
- Customer Experience: Reduced false declines by 40%, improving customer satisfaction while maintaining fraud catch rates
- Regulatory Compliance: Implemented explainable AI systems meeting regulatory requirements, supported successful audits
- Technology Leadership: Transitioned organizations from rule-based to ML-driven fraud detection, built scalable real-time scoring infrastructure
Conclusion: Fraud detection sits at the intersection of machine learning, domain expertise, data engineering, and business strategy. Success requires not only technical proficiency in ML algorithms but also creativity in feature engineering, understanding of fraud typologies, and ability to balance competing business objectives. The field continues evolving rapidly as both fraud techniques and detection technologies advance. My work demonstrates end-to-end capability from data acquisition through model deployment to business impact measurement, positioning me to tackle fraud challenges across industries and fraud types.