Collaborative labelling tool
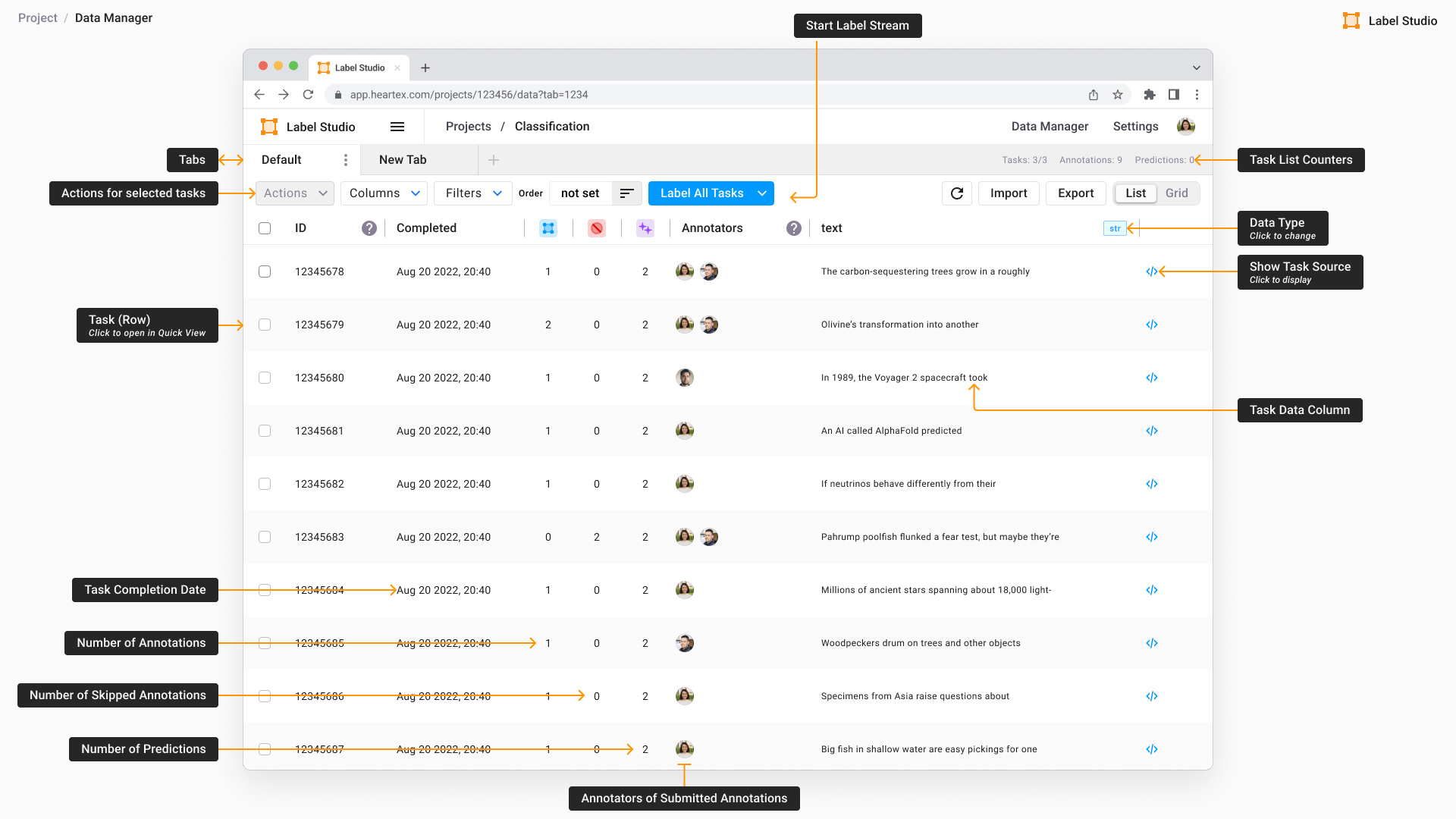 Label Studio
Label Studio
The Data Annotation Challenge: Machine learning models are only as good as the data they're trained on. High-quality annotated datasets are the foundation of successful ML projects, yet data labeling represents a critical bottleneck in the ML development lifecycle. Industry research consistently shows that data preparation, including annotation, consumes 60-80% of total project time—more than model development, deployment, and maintenance combined.

Project Context: In our NLP chatbot development initiative, we needed annotated conversational data—thousands of customer utterances labeled with intents (what the user wants) and entities (key information like dates, locations, product names). Previously, annotation was performed in spreadsheets—a tedious, error-prone process lacking collaboration features, version control, quality metrics, or integration with ML pipelines.
Project Objective: Design and implement a collaborative annotation platform that:
- Reduces annotation time by 40%+ through intelligent UI and active learning
- Enables real-time collaboration among distributed annotation teams
- Provides quality assurance through inter-annotator agreement metrics
- Integrates ML-assisted pre-annotation to leverage existing models
- Supports iterative model improvement through continuous annotation-training loops
- Handles multiple data types (text, images, audio) for future expansion
Technical Solution: After comprehensive evaluation of open-source annotation platforms (Label Studio, Prodigy, Doccano, CVAT), I selected and customized Label Studio for our requirements, deployed it on AWS infrastructure with CI/CD pipelines, and integrated it with our ML training workflows.
Platform Architecture & Technical Implementation
Technology Selection - Why Label Studio?
Evaluation Criteria: Our selection process evaluated platforms across multiple dimensions: feature completeness, extensibility, deployment flexibility, community support, license compatibility, and ML integration capabilities.
Label Studio Advantages:
- Multi-Modal Support: Handles text, images, audio, video, HTML, time-series data with unified interface—enables future project expansion beyond NLP
- Flexible Configuration: XML-based annotation interface configuration allows custom labeling schemas without code changes
- ML Integration: Native support for ML-assisted annotation through prediction backends, enabling active learning workflows
- Collaboration Features: Multi-user annotation, task assignment, annotation review workflows, quality metrics
- API-First Design: Comprehensive REST API enables automation, integration with ML pipelines, custom tooling
- Open Source: Apache 2.0 license with active community, extensible through plugins
- Deployment Flexibility: Runs as standalone app, Docker container, or cloud deployment
System Architecture

Infrastructure Components:
- Label Studio Application: Deployed on AWS EC2 with auto-scaling based on user count, containerized using Docker for reproducibility
- PostgreSQL Database: Managed AWS RDS for annotation data, project configurations, user management with automated backups
- Object Storage (S3): Stores raw data (audio files, images, documents) separately from annotation database, enabling efficient data access
- ML Prediction Backend: Custom Flask/FastAPI service hosting trained models for pre-annotation, deployed on separate compute instances for scalability
- Task Queue (Celery/Redis): Asynchronous task processing for bulk imports, export generation, prediction computation
- Load Balancer (AWS ALB): Distributes traffic, handles SSL termination, enables zero-downtime deployments
- Monitoring Stack: Prometheus + Grafana for system metrics, application logs aggregated in CloudWatch
Security & Access Control:
- OAuth2/SAML integration with corporate identity provider for single sign-on
- Role-based access control (RBAC): admin, annotator, reviewer roles with granular permissions
- Project-level isolation ensuring annotators only access assigned datasets
- Audit logging of all annotation actions for quality tracking and compliance
- Data encryption at rest and in transit
CI/CD Pipeline:
- GitLab CI/CD for automated testing and deployment
- Automated database migrations using Alembic
- Blue-green deployment strategy for zero-downtime updates
- Automated backup verification and disaster recovery testing
User Experience & Annotation Workflow
Onboarding & Account Management
User Registration: New annotators create accounts through SSO integration or email invitation system. Account creation triggers automated onboarding workflow:
- Interactive tutorial walking through annotation interface
- Sample annotation tasks with instant feedback
- Documentation access (annotation guidelines, FAQs, video tutorials)
- Quality certification—users complete test annotations before accessing production tasks
Security Benefits: Individual accounts enable:
- Detailed productivity tracking (tasks completed, time spent, quality metrics)
- Personalized task assignment based on expertise and performance
- Access revocation without disrupting other users
- Audit trails attributing every annotation to specific user
Intelligent Annotation Interface
NLP Intent & Entity Annotation: The annotation interface is optimized for speed and accuracy:
Layout Design:
- Top Section - Entity Recognition:
- Primary text displayed prominently with clear typography
- Entity palette showing available entity types (date, location, person, product, etc.) with keyboard shortcuts
- Mouse highlighting workflow: Select entity type, click-and-drag to highlight entity span
- Alternative keyboard workflow: Highlight text first, press hotkey for entity type
- Visual distinction of entities through color coding and labels
- Nested entity support for complex annotations
- Bottom Section - Intent Classification:
- Hierarchical intent taxonomy displayed as expandable tree or tag cloud
- ML prediction highlighted with confidence score (e.g., "85% confident: Order_Status_Inquiry")
- Single-click confirmation if prediction is correct
- Search functionality for quickly finding intent from 100+ options
- Recent intents panel showing annotator's last selections for repetitive tasks
- Multi-label support where utterance has multiple intents
- Context Panel (Collapsible):
- Previous conversation turns for context (chatbot annotations need dialogue history)
- Similar examples from training set with their annotations
- Annotation guidelines specific to current project
- Notes field for annotator comments on ambiguous cases
Productivity Features:
- Keyboard Shortcuts: Navigate between tasks (J/K keys), submit (Enter), skip (S), undo (Ctrl+Z) without touching mouse
- Bulk Actions: Apply same label to multiple similar tasks, propagate entity annotations
- Auto-save: Annotations automatically saved as annotator works, preventing data loss
- Smart Suggestions: As annotator types in search, system suggests similar entities from existing annotations
- Progress Tracking: Real-time counter showing completed/remaining tasks, estimated time to completion
ML-Assisted Pre-Annotation
The Game-Changer: Rather than starting from scratch, annotators review and correct ML model predictions, reducing annotation time by 60%+ for high-confidence predictions.
Prediction Backend Integration:
- Real-time Inference: When annotator opens task, Label Studio sends text to prediction API
- Model Serving: Custom Flask service hosting fine-tuned CamemBERT model for French intent classification, spaCy NER model for entity recognition
- Prediction Display: Predictions pre-filled in annotation interface with visual indicators:
- High confidence (>90%): Green border, "likely correct" label
- Medium confidence (70-90%): Yellow border, "please verify" label
- Low confidence (<70%): Red border, "low confidence" warning
- Annotator Workflow: Most tasks reduce to verification—confirm correct predictions, fix incorrect ones—dramatically faster than annotation from scratch
Confidence-Based Task Routing:
- Low confidence predictions routed to senior annotators for careful review
- High confidence predictions routed to junior annotators for quick verification
- Ambiguous cases flagged for multi-annotator consensus
Quality Assurance Mechanisms
- Inter-Annotator Agreement: Randomly select 10% of tasks for dual annotation, compute Cohen's Kappa to measure consistency
- Expert Review Workflow: Senior annotators review samples of each junior annotator's work, provide feedback
- Gold Standard Tasks: Pre-annotated tasks with known correct labels inserted into workflows to monitor annotator accuracy
- Disagreement Resolution: Tasks with low inter-annotator agreement escalated to expert arbitrators
- Quality Dashboards: Real-time visualization of annotator-level metrics:
- Agreement with expert annotations
- Agreement with other annotators
- Average annotation time (detect rushing or confusion)
- Productivity trends over time
- Common error patterns
Active Learning Strategy - Maximizing Annotation ROI
The Fundamental Problem: Random annotation wastes resources. Annotating easy examples the model already handles correctly provides minimal value. Conversely, strategically selecting informative examples for annotation dramatically improves model performance per annotation hour invested.
Active Learning Philosophy: Let the model tell us which examples it's confused about—those are the most valuable to annotate. This creates a virtuous cycle: better annotations → better models → smarter sample selection → more efficient annotation.
Active Learning Pipeline
Step 1: Bootstrap with Manual Annotation
- Initial Dataset: Manually annotate 1,000-2,000 representative examples covering main intents and entity types
- Stratification: Ensure balanced representation across intent classes to prevent initial model bias
- Quality Focus: Invest extra time in annotation guidelines and consistency for this seed dataset—it sets foundation for everything else
- Typical Timeline: 2-3 weeks with team of 3-4 annotators
Step 2: Train Initial Model
- Architecture: Fine-tune CamemBERT for intent classification, train spaCy NER for entities
- Validation Split: Hold out 20% of seed data for validation to estimate model performance
- Performance Baseline: Initial model typically achieves 70-75% accuracy—good enough to provide useful predictions but lots of room for improvement
- Deployment: Deploy model as prediction backend integrated with Label Studio
Step 3: Score Unlabeled Data
- Batch Inference: Run model on entire unlabeled dataset (50K+ examples)
- Uncertainty Quantification: For each prediction, compute uncertainty metrics:
- Least Confidence: 1 - P(predicted class) — high values indicate low confidence
- Margin Sampling: P(top class) - P(second class) — small margins indicate confusion between top candidates
- Entropy: -Σ P(c) log P(c) — high entropy indicates spread-out probability distribution
- Diversity Consideration: Don't only select uncertain examples—ensure diversity to avoid annotation redundancy. Use clustering to identify representative examples from different regions of feature space
Step 4: Prioritize Annotation Queue
- Uncertainty-Based Ranking: Sort unlabeled examples by uncertainty score (highest uncertainty first)
- Diversity Sampling: Within high-uncertainty pool, select diverse examples to maximize information gain
- Stratified Sampling: Ensure coverage of rare classes/entities that might be underrepresented in uncertainty rankings
- Business Priority Weighting: Boost priority of examples from high-value user segments or critical business flows
- Batch Selection: Select 500-1000 examples for next annotation batch
Step 5: Annotate Selected Batch
- Import to Label Studio: Load prioritized batch with model predictions as pre-annotations
- Distributed Annotation: Assign tasks across annotation team based on expertise and availability
- Faster Annotation: Because model is better now, more predictions are correct, annotation is faster than initial seed data
- Quality Checks: Continue inter-annotator agreement checks and expert review
Step 6: Retrain Model on Expanded Dataset
- Combine Data: Merge new annotations with existing training set
- Incremental Training: For large datasets, use incremental learning to update model without full retraining
- Validation: Evaluate on held-out validation set to track improvement
- A/B Testing: Compare new model against previous version on live traffic to confirm improvement
- Deployment: Update prediction backend with improved model
Step 7: Iterate
- Return to Step 3 with improved model
- Each iteration: model gets better → predictions more accurate → annotation faster → more data labeled → model improves further
- Continue until model performance meets business requirements or marginal improvements diminish
- Convergence Criteria: Stop when validation accuracy plateaus or cost of annotation exceeds value of improvements
Results & Impact
Quantitative Results:
- Annotation Efficiency: Active learning required 40% fewer annotations to reach 90% accuracy compared to random sampling
- Time Savings: Achieved target accuracy in 8 weeks vs. estimated 14 weeks with random annotation
- Cost Reduction: Saved approximately $30K in annotation costs (400 hours at $75/hr)
- Model Performance: Final model achieved 92% intent accuracy, 88% entity F1 score
- Annotation Speed: Average annotation time decreased from 45 seconds per example (seed data) to 12 seconds (final iterations with high-quality predictions)
Qualitative Benefits:
- Annotator Satisfaction: Reduced tedium through ML assistance, increased sense of productivity and impact
- Focus on Hard Cases: Annotators spent time on genuinely ambiguous examples requiring human judgment, not mindless labeling
- Improved Guidelines: Difficult cases surfaced by active learning helped refine annotation guidelines
- Better Coverage: Diverse sampling ensured model learned from full spectrum of user inputs, not just common patterns
Technical Challenges & Solutions
- Cold Start Problem: Initial model is weak, provides poor predictions. Solution: Invest in high-quality seed dataset, accept slower annotation initially, benefits compound quickly
- Model Bias: Model might be systematically confident about certain types of errors. Solution: Combine uncertainty sampling with diversity sampling and stratified sampling
- Feedback Loops: If model only sees examples it's uncertain about, it might not learn rare patterns. Solution: Include random sampling component (10-20%) to maintain exploration
- Computational Cost: Scoring entire unlabeled dataset can be expensive. Solution: Batch inference on GPU, cache predictions, update only periodically (every N annotations)
- Distribution Shift: Training set becomes biased toward difficult examples. Solution: Maintain balanced sampling, periodically include random samples, monitor validation set representing true distribution
Extensions & Advanced Techniques
- Ensemble Uncertainty: Train multiple models with different initializations, use prediction disagreement as uncertainty measure
- Monte Carlo Dropout: Stochastic forward passes with dropout enabled to estimate prediction uncertainty
- Query-by-Committee: Maintain diverse model ensemble, select examples where committee members disagree most
- Expected Model Change: Estimate how much model parameters would change if example were added to training set, prioritize high-impact examples
- Human-in-the-Loop Retraining: Automatically trigger model retraining when sufficient new annotations accumulated
- Transfer Learning from Related Tasks: Bootstrap with models trained on similar datasets (other companies' chatbots, public NLP datasets) to improve initial performance